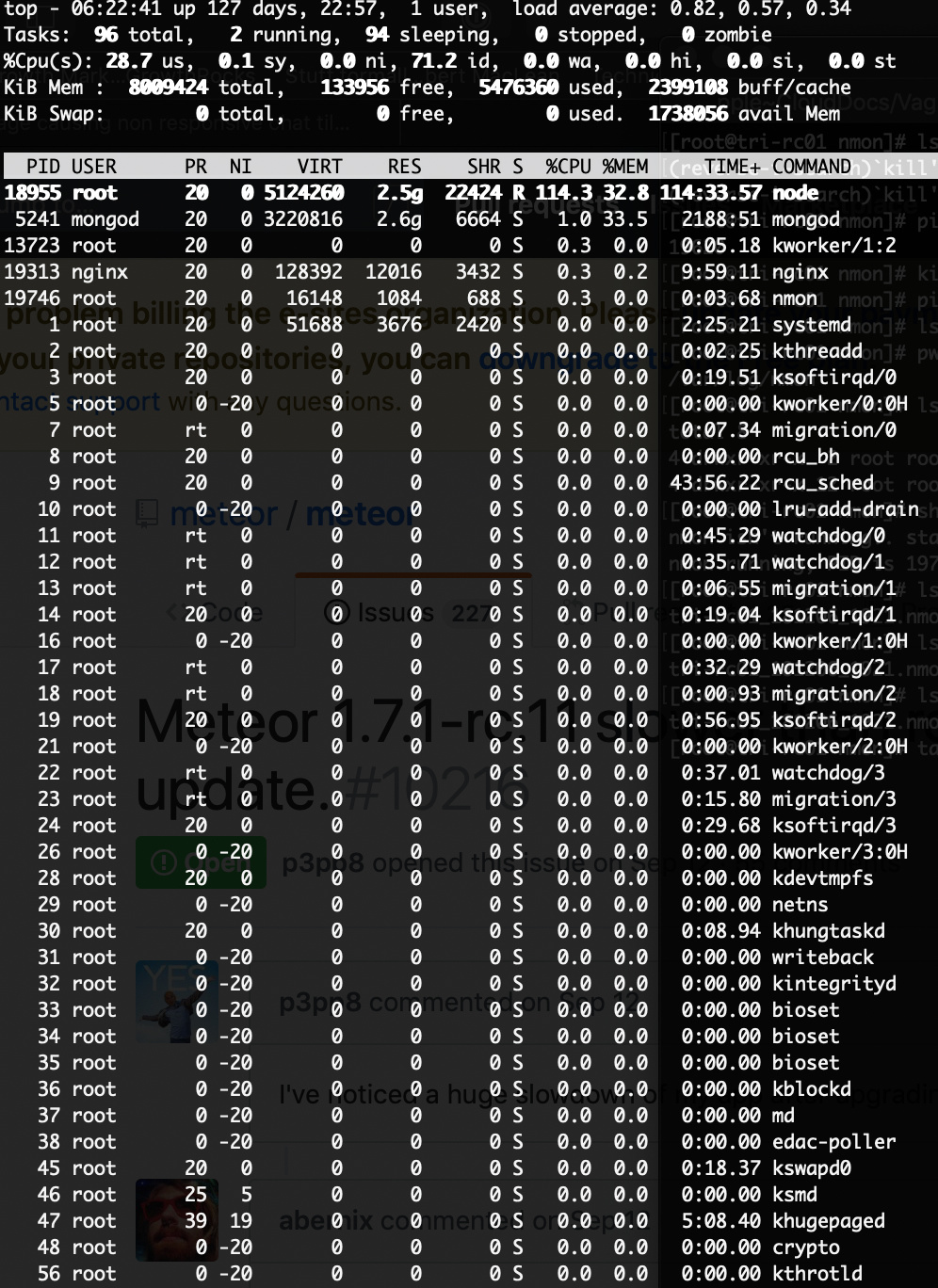
Since a few days Rocket Chat is using 100% CPU from time to time. It stays using 100% till I restart the service. During that 100% CPU usage the entire chat becomes unresponsive.
First I thought it was related to the API usage for setting / uploading avatars to RC however I disabled this flow and the issue remains. The only thing that did change over the past days is the upgrade from 0.71 to 0.72, Yesterday I upgraded to 0.72.1 however the problem remains.
Going trough the changelog of 0.72 I don’t see anything that might cause this 100% CPU usage in our case. It also doesn’t happen on the same hour of day.
Below two screenshots of the CPU spike that stays on till I restart the process.
Screenshot1:

Screenshot2:

Logs
I don’t see anything that jumps out of the logs that wasn’t there earlier. I do log exceptions swell now to a RC channel but the errors don’t align time wise with the outages.
Exceptions:
Exception in added observe/observeChanges callback:
TypeError: Cannot destructure property `username` of 'undefined' or 'null'.
BulkWriteError: E11000 duplicate key error collection:
rocketchat.rocketchat_message index: _id_ dup key: { : "G9oJAbj6iYRqHxLjo" }
Log:
Dec 3 04:01:01 tri-rc01 systemd: Removed slice User Slice of root.
Dec 3 04:01:01 tri-rc01 systemd: Stopping User Slice of root.
Dec 3 04:01:01 tri-rc01 systemd: Created slice User Slice of root.
Dec 3 04:01:01 tri-rc01 systemd: Starting User Slice of root.
Dec 3 04:01:01 tri-rc01 systemd: Started Session 3238 of user root.
Dec 3 04:01:01 tri-rc01 systemd: Starting Session 3238 of user root.
Dec 3 04:01:01 tri-rc01 systemd: Removed slice User Slice of root.
Dec 3 04:01:01 tri-rc01 systemd: Stopping User Slice of root.
Dec 3 04:09:20 tri-rc01 rocketchat: The endpoint "permissions" is deprecated and will be removed after version v0.69
Dec 3 04:15:08 tri-rc01 rocketchat: TypeError: Cannot read property 'getRedirectURL' of undefined
Dec 3 04:15:08 tri-rc01 rocketchat: at FileUploadClass.copy (/opt/Rocket.Chat/programs/server/packages/rocketchat_file-upload.js:1008:30)
Dec 3 04:15:08 tri-rc01 rocketchat: at Object.copy (/opt/Rocket.Chat/programs/server/packages/rocketchat_file-upload.js:627:13)
Dec 3 04:15:08 tri-rc01 rocketchat: at copyFile (/opt/Rocket.Chat/programs/server/packages/rocketchat_user-data-download.js:272:20)
Dec 3 04:15:08 tri-rc01 rocketchat: at exportOperation.fileList.forEach.attachmentData (/opt/Rocket.Chat/programs/server/packages/rocketchat_user-data-download.js:536:9)
Dec 3 04:15:08 tri-rc01 rocketchat: at Array.forEach (<anonymous>:null:null)
Dec 3 04:15:08 tri-rc01 rocketchat: at continueExportOperation (/opt/Rocket.Chat/programs/server/packages/rocketchat_user-data-download.js:535:32)
Dec 3 04:15:08 tri-rc01 rocketchat: at cursor.forEach.exportOperation (/opt/Rocket.Chat/programs/server/packages/rocketchat_user-data-download.js:577:5)
Dec 3 04:15:08 tri-rc01 rocketchat: at SynchronousCursor.forEach (/opt/Rocket.Chat/programs/server/packages/mongo.js:1120:16)
Dec 3 04:15:08 tri-rc01 rocketchat: at Cursor.(anonymous function) [as forEach] (/opt/Rocket.Chat/programs/server/packages/mongo.js:918:44)
Dec 3 04:15:08 tri-rc01 rocketchat: at Object.processDataDownloads [as job] (/opt/Rocket.Chat/programs/server/packages/rocketchat_user-data-download.js:572:10)
Dec 3 04:15:08 tri-rc01 rocketchat: at packages/littledata_synced-cron.js:251:26
Dec 3 04:15:08 tri-rc01 rocketchat: at scheduleTimeout (packages/littledata_synced-cron.js:304:9)
Dec 3 04:15:08 tri-rc01 rocketchat: at packages/littledata_synced-cron.js:356:42
Dec 3 04:15:08 tri-rc01 rocketchat: at Meteor.EnvironmentVariable.EVp.withValue (packages/meteor.js:1304:12)
Dec 3 04:15:08 tri-rc01 rocketchat: at packages/meteor.js:620:25
Dec 3 04:15:08 tri-rc01 rocketchat: at runWithEnvironment (packages/meteor.js:1356:24)
Dec 3 04:25:10 tri-rc01 rocketchat: The endpoint "permissions" is deprecated and will be removed after version v0.69
Setup and server information:
type: VPS, only running RC and MongoDB
CPU: 4 core
RAM: 8GB
Number of users online: 50-300
Operating System: CentOS Linux release 7.6.1810
Version of Rocket.Chat Server: 0.72.1
Deployment Method: tar
Number of Running Instances: 1
Oplog: disabled
NodeJS Version: 8.12.0
MongoDB Version: v3.2.21
Node Version: v8.11.4